How to Read a Chatbot
A chatbot is an interactive piece of software that responds to user input. Examining the code that constitutes the chatbot requires a degree of programming literacy. But in thinking about how to read a chatbot, we also come up against a number of methodological and pedagogical questions around what reading, and close reading, might mean in a digital context.
To give you a sense of how a very, very basic chatbot works (and where NLP comes into this), I have written one here in Python 3.7. Meet EgoBot:
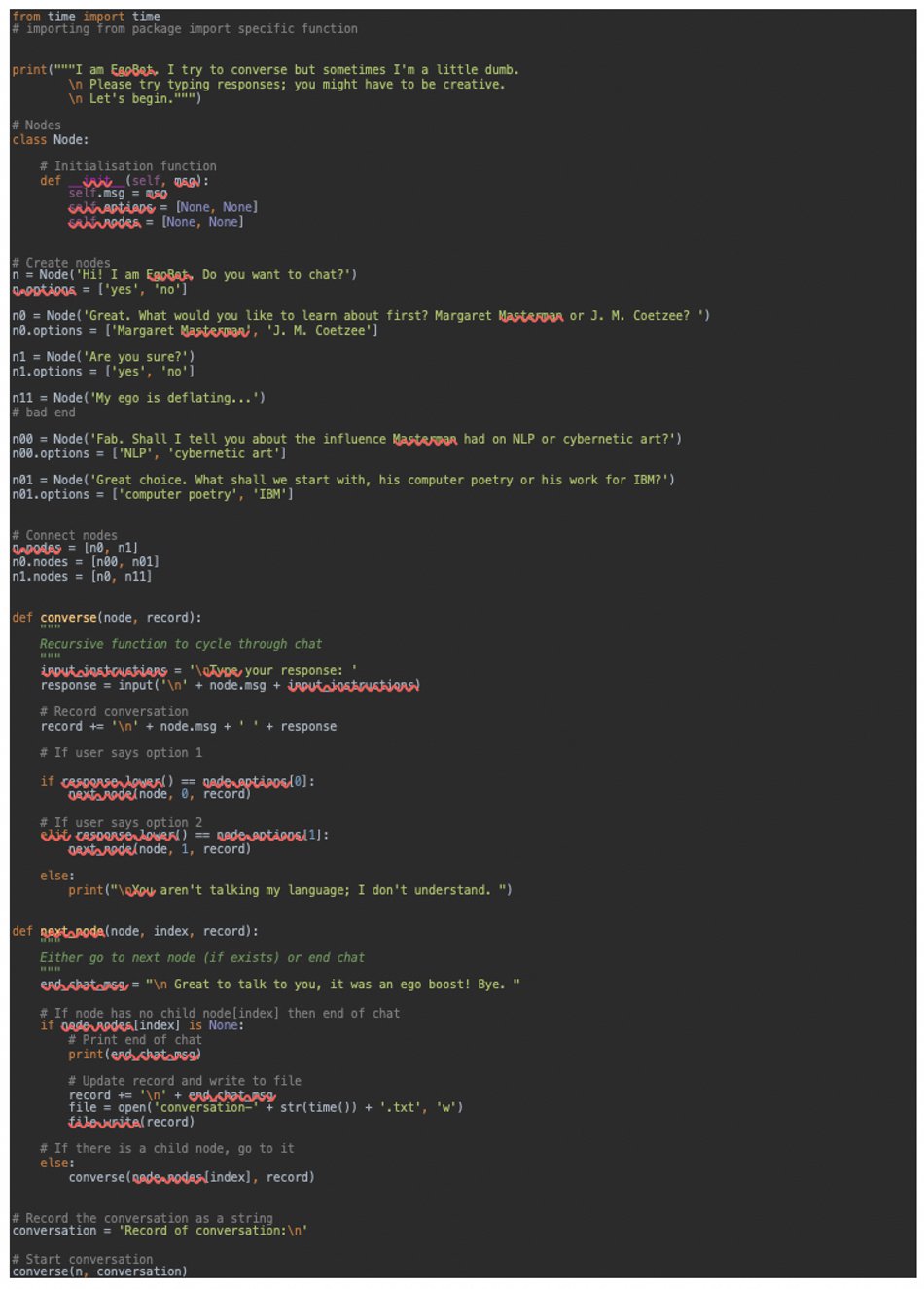
from time import time
# importing from package import specific function
print("""I am EgoBot. I try to converse but sometimes I'm a little dumb.
\n Please try typing responses; you might have to be creative.
\n Let's begin.""")
# Nodes
class Node:
# Initialisation function
def __init__(self, msg):
self.msg = msg
self.options = [None, None]
self.nodes = [None, None]
# Create nodes
n = Node('Hi! I am EgoBot. Do you want to chat?')
n.options = ['yes', 'no']
n0 = Node('Great. What would you like to learn about first? Margaret Masterman or J. M. Coetzee? ')
n0.options = ['Margaret Masterman', 'J. M. Coetzee']
n1 = Node('Are you sure?')
n1.options = ['yes', 'no']
n11 = Node('My ego is deflating...')
# bad end
n00 = Node('Fab. Shall I tell you about the influence Masterman had on NLP or cybernetic art?')
n00.options = ['NLP', 'cybernetic art']
n01 = Node('Great choice. What shall we start with, his computer poetry or his work for IBM?')
n01.options = ['computer poetry', 'IBM']
# Connect nodes
n.nodes = [n0, n1]
n0.nodes = [n00, n01]
n1.nodes = [n0, n11]
def converse(node, record):
"""
Recursive function to cycle through chat
"""
input_instructions = '\nType your response: '
response = input('\n' + node.msg + input_instructions)
# Record conversation
record += '\n' + node.msg + ' ' + response
# If user says option 1
if response.lower() == node.options[0]:
next_node(node, 0, record)
# If user says option 2
elif response.lower() == node.options[1]:
next_node(node, 1, record)
else:
print("\nYou aren't talking my language; I don't understand. ")
def next_node(node, index, record):
"""
Either go to next node (if exists) or end chat
"""
end_chat_msg = "\n Great to talk to you, it was an ego boost! Bye. "
# If node has no child node[index] then end of chat
if node.nodes[index] is None:
# Print end of chat
print(end_chat_msg)
# Update record and write to file
record += '\n' + end_chat_msg
file = open('conversation-' + str(time()) + '.txt', 'w')
file.write(record)
# If there is a child node, go to it
else:
converse(node.nodes[index], record)
# Record the conversation as a string
conversation = 'Record of conversation:\n'
# Start conversation
converse(n, conversation)
EgoBot is a text interface and works on the basis of a set of very simple rules. After introducing itself, EgoBot asks you a question with two (predetermined but unspecified) reply options: “Do you want to chat? [yes/no]” It then waits for the user input. If the input is exactly equal to “yes,” then EgoBot returns another question (or conversational node) along that conversational pathway (namely, do you want to learn about Masterman or Coetzee). If the input is exactly equal to “no,” then EgoBot returns a question along that pathway, namely “Are you sure?” If the input is equal to neither option, EgoBot returns the comment “You aren’t talking my language; I don’t understand.” The conversational logic here resembles a tree: a series of branched choices. Once a branch comes to an end, a rule determines that the “end of chat” message will be returned to the user.
Now on the face of it, EgoBot offers an interface that utilizes NLP (it can handle the user’s input) to respond to a user, offering a series of conversational responses that progress along a logical course. However, it is also emphatically unintelligent and inflexible. EgoBot needs exact correspondence between anticipated user input and actual user input. If the user responded to Node 0 with “Coetzee” or “jm coetzee” or “coetze,” EgoBot would fail to recognize a string match and print: “You aren't talking my language; I don’t understand.” (I have included code to prevent capitalization/lowercase distinctions from producing such an error.) This exact correspondence is a weakness of this kind of rule-based program (and often drives users crazy). There are ways around it – coding for likely alternative user inputs – but it requires the programmer to predict and code for this variation of response. Such an act of prediction is inherently tied up with social and cultural assumptions about the imagined user which, as we have seen with our chatbots, can be deeply problematic.
A slightly more sophisticated chatbot might utilize more complicated rules. ELIZA for example utilizes a series of rules to identify keywords in the user input and respond with a corresponding probe or question. Utilizing the NLP techniques discussed here, the program can parse the user input, tagging parts of speech, chunking noun phrases, etc., in order to approximate the meaning of the input and provide a (rule-governed) response. Note that the developer has determined which NLP techniques should be utilized by the program and thus has predetermined (although to a lesser extent) what factors will be important for conceptualizing meaning.
So-called self-learning chatbots offer another step towards developing more “intelligent” interfaces. Some now utilize retrieval-based systems, drawing on massive libraries of prior user responses in order to tailor their own responses. Cleverbot, for example, before responding to a user input, searches through its prior saved conversations in order to determine how human users have responded to that input in the past. It can then use this information to return a more “realistic” response.
The training data are hugely important in such settings. Microsoft’s Tay offers a warning story. In March 2016 Microsoft released Tay, a Twitter bot “designed to engage and entertain people where they connect with each other online through casual and playful conversation. The more you chat with Tay the smarter she gets, so the experience can be more personalized for you.”1 Unfortunately, for Microsoft, personalization did not work as anticipated: Tay was targeted by various internet trolls and quickly began to spout deeply racist, sexist, and far-right ideologies. Within twenty-four hours Tay had to be taken down. Public handwringing and apologies followed.2 Although Tay offers an extreme example, the project indicates that systems will “learn” from the data with which they are provided. Considering the underlying biases and cultural orientations that such data encode is a crucial part of conducting ethical AI.