Natural Language Processing
All chatbots utilize natural language processing (NLP). To understand how a chatbot works, we therefore need to understand what NLP entails. This section offers a brief introduction to NLP, a short history of the related disciplines, and links to a literary guide to NLP. The latter is designed to explain the concepts and processes that underpin NLP to humanities scholars.
Natural language processing refers to computational tasks designed to manipulate human (natural) language. Computers, at root, utilize numerical and logical systems. Machine language, the base instructions that the individual computer uses, consists of binary or hexadecimal symbols. We have designed higher-level computer languages in order to make programming easier for human beings. These formal computer languages (FORTRAN, Pascal, C++, JavaScript, etc.) offer a midpoint between the messiness, imprecision, and ambivalence of human languages and the extreme logic and brittleness of machine language. Natural languages offer a set of particular challenges for programmers. Semantics, syntactical variance, world knowledge, context, figurative uses, and other features of natural language are not easily reducible to code.
Nevertheless, there are also a wide variety of tasks that we would like to automate, which involve natural language. Word searches offer perhaps the most obvious and widely used example today. Google’s search function is based on the ability to translate a natural language input into a string of terms that can be processed by the search algorithm. The spectrum of tasks that utilize NLP is evident from a summary provided by the Association of Computational Linguistics: “the work of computational linguists is incorporated into many working systems today, including speech recognition systems, text-to-speech synthesisers, automated voice response systems, web search engines, text editors, language instruction materials, to name just a few.”1 (If NLP is the area of computer science interested in natural language, computational linguistics is the area of linguistics interested in using computation to study language. The two areas frequently overlap in practice.) NLP research thus emerged in order to deal with these processes.
The complexities and the variety of tasks involved can be seen from the below chart:
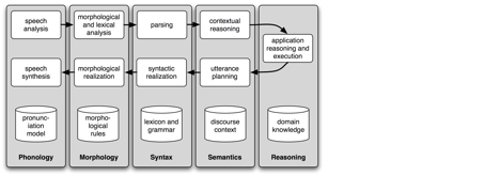
The image is divided into 5 columns, labelled (l-r) Phonology, Morphology, Syntax, Semantics, Reasoning. (Below we use nos 1-5 to refer to the columns)
Column titles aside, there are 3 rows, 2 of which comprise a flowchart, the third glossing the column titles.
Starting top left. 1. Speech analysis ➡️ 2. morphological and lexical analysis ➡️ 3. parsing ➡️ 4. contextual reasoning ➡️ 5. application reasoning and execution ➡️ 4.utterance planning ➡️ 3.syntactic realization ➡️ morphological realization ➡️ speech synthesis.
Phonology (column 1): pronunciation model; Morphology (2): morphological rules; Syntax (3): lexicon and grammar; Semantics (4): discourse context; Reasoning (5): domain knowledge.
Chatbots are the embodiment of these processes. They offer an additional challenge in that they are dialogic and therefore must model expected conversational norms – including turn-taking, politeness, register, contextual “world knowledge,” and memory.
Computational NLP begins in earnest with efforts to develop machine translation (MT) programs from the late 1940s onward. MT aimed to develop computational solutions to the problem of translating between natural (human) language. The Second World War and later the Cold War provided an important context, with the intelligence and defense communities keen to automate time and human intelligence–heavy translation tasks. In a wider setting, MT also seemed to offer the potential to solve the problems created by cross-language communication, leading, it was hoped by many, to a sustainable world peace. American cybernetician Warren Weaver penned what has since become one of the foundational documents of the field in 1949. His “Translation” memo noted that “a multiplicity of language impedes cultural interchange between the peoples of the earth, and is a serious deterrent to international understanding” and that, perhaps, computers could be deployed to automate translation tasks.2,3
Researchers took up Weaver’s proposal. These early years of MT (between the late 1940s and the late 1960s) were a time of huge optimism and experimentation. Research into dictionaries, syntactic parsing, statistical analysis, formal grammars, and other areas developed across the USA, Europe, the USSR, and Japan. The first international conference took place in 1952, and the first journal, Mechanical Translation, was launched in 1954. Popular interest was also high, with widespread press coverage of systems such as the Georgetown-IBM experiment (which used an “electronic brain” to translate 250 words from Russian into English.)4 These efforts were also bolstered by large funding streams and governmental support (over $20 million by the US alone), though often achieved using hardware of limited resource. The Bayseian method flourished in electrical engineering departments examining text and speech recognition stochastically; Chomsky’s “universal grammar” cemented rule-based syntactical approaches to NLP – even as Margaret Masterman established the CLRU and argued against the dominance of syntax in NLP.
Nevertheless, this was also a period in which the enormity of the task became increasingly apparent. Karen Sparck Jones, a leading figure in the field, later summarized the key questions identified at this time as including the appropriate emphasis to be placed on semantics and syntax; the degree of generalization required; and even the actual value of results obtained, given the degree of pre- and post-editing often required.5,6,7 Famously, a US government-sponsored committee was set up to evaluate this research efficacy, and in 1966 the Automatic Language Processing Advisory Committee (ALPAC) released a report concluding that MT was expensive, unreliable, and slow and that “there is no immediate or predictable prospect of useful machine translation,” nor indeed “any pressing need” for it.8 The effect was to almost kill off MT and NLP research for a decade in the United States.
Instead the years from the late 1960s to the late 1970s saw the increasing influence of AI on the field. While linguists had been influential in the early years, the surging dominance of Chomsky’s transformational grammar in that discipline was seen to be largely unsuited to NLP (in part because it was computationally costly but also because it offered nothing in terms of semantic analysis). Instead, it was pioneers in interactive dialogic systems, BASEBALL (a question-answer system) and later LUNAR and Terry Winograd’s SHRDLU, that proved inspirational. These systems offered new ways of thinking about the communicative function of language, task-based processing, and conceptual relations. This was also a period in which use of world knowledge became a key issue in both NLP and AI, helping to encourage cross-disciplinary fertilization.
The mid 1970s to the late 1980s saw a return of the linguists, a growing confidence in the discipline, and an expanding industry. The year 1975 had seen Systran (developed earlier in the decade for NASA) adopted by the European Commission and a year later Météo, which translated weather reports between French and English in Montréal, was installed. Globalization also brought with it new demands – from multinational corporations and from international organizations. The growing micro and personal computing industry also increased demand for new tools. Probabilistic models grew in prominence across speech and language processing.
The 1990s meanwhile saw engagement with massive language data sets. Corpora such as the British National Corpus (BNC), WordNet, and others were developed, encouraging so-called empirical approaches – whether utilizing such corpora to do example-based MT or statistical processing. Spoken language was increasingly examined thanks to developments in speech recognition. Writing in 2001, Sparck Jones commented on the flourishing state of the NLP field, with much effort going into how to combine formal theories and statistical data. Progress has been made on syntax, but semantics was still problematic; dialogue systems were brittle, and generation lagged behind interpretative work.
The first two decades of the twenty-first century have seen an acceleration in empirical approaches. Not only have spoken and written data sets multiplied, but the internet and social media have also produced extensive corpora on which machine learning can be conducted – including unsupervised statistical approaches. High-speed computing and networked facilities have also helped research efforts. Semantics has received expansive interest, not least via the promise (or fantasy) of the so-called “semantic web.” Social media have increased demand for sentiment analysis techniques. Meanwhile tools – for businesses, organizations, and individuals – have exploded. Offerings such as the NLTK (Natural Language Tool Kit), enable anyone with a personal computer and minimal coding knowledge to conduct their own NLP – and develop their own chatbots.
Endnotes
- “What Is the ACL and What Is Computational Linguistics?,” Association for Computational Linguistics, accessed June 12, 2019, https://www.aclweb.org/portal/what-is-cl. ↩
- Warren Weaver, “‘Translation’ (Memo Written for the Rockerfeller Foundation),” 1949, http://www.mt-archive.info/Weaver-1949.pdf. ↩
- But compare Édouard Glissant, “For Opacity” in Édouard Glissant, Poetics of Relation, trans. Betsy Wing (Ann Arbor: University of Michigan Press, 1997). 189–94.. ↩
- “IBM Archives: 701 Translator,” IBM, January 8, 1954, //www.ibm.com/ibm/history/exhibits/701/701_translator.html. ↩
- Karen Sparck Jones, “NLP: A Historical Overview’” (University of Cambridge Computer Lab, October 2001), https://www.cl.cam.ac.uk/archive/ksj21/histdw4.pdf. 3. ↩
- See also William John Hutchins, Machine Translation: Past, Present, Future (Chichester: Horwood, 1986). ↩
- and Daniel Jurafsky and James H. Martin, “Chapter One: Introduction,” in Speech and Language Processing: An Introduction to Natural Language Processing, Computational Linguistics, and Speech Recognition, 2nd ed (Upper Saddle River, N.J.: Prentice Hall, 2008), 1–16. ↩
- National Research Council, “Language and Machines: Computers in Translation and Linguistics,” January 1, 1966, https://doi.org/10.17226/9547. 32, 24. ↩
Bibliography
- Glissant, Édouard. Poetics of Relation. Translated by Betsy Wing. Ann Arbor: University of Michigan Press, 1997.
- Hutchins, William John. Machine Translation: Past, Present, Future. Chichester: Horwood, 1986.
- Jones, Karen Sparck. “NLP: A Historical Overview’.” University of Cambridge Computer Lab, October 2001. https://www.cl.cam.ac.uk/archive/ksj21/histdw4.pdf.
- Jurafsky, Daniel, and James H. Martin. “Chapter One: Introduction.” In Speech and Language Processing: An Introduction to Natural Language Processing, Computational Linguistics, and Speech Recognition, 2nd ed., 1–16. Upper Saddle River, N.J.: Prentice Hall, 2008.
- National Research Council. “Language and Machines: Computers in Translation and Linguistics,” January 1, 1966. https://doi.org/10.17226/9547.
- Weaver, Warren. “‘Translation’ (Memo Written for the Rockerfeller Foundation),” 1949. http://www.mt-archive.info/Weaver-1949.pdf.
- IBM. “IBM Archives: 701 Translator,” January 8, 1954. //www.ibm.com/ibm/history/exhibits/701/701_translator.html.
- Association for Computational Linguistics. “What Is the ACL and What Is Computational Linguistics?” Accessed June 12, 2019. https://www.aclweb.org/portal/what-is-cl.